
I'm a graduate student of M.Eng. in Robotics at the University of Maryland, College Park. I am interested in working on the applications of machine learning. I have experience with working on image processing algorithms, both the classical and the deep learning methods.
I am highly motivated and proactive at developing my knowledge and in advancing my experience. Over the past year, I have dived my expertise in the pool of ML and AI. Since I find these concepts extremely inquisitive, most of my course work is related to this field. I cannot put into words how excited I am about the application of robotics in various areas and how it can improve the world around us.
When I'm not in front of a computer screen dipped into robotics, I'm probably traveling, cooking, or playing sports.
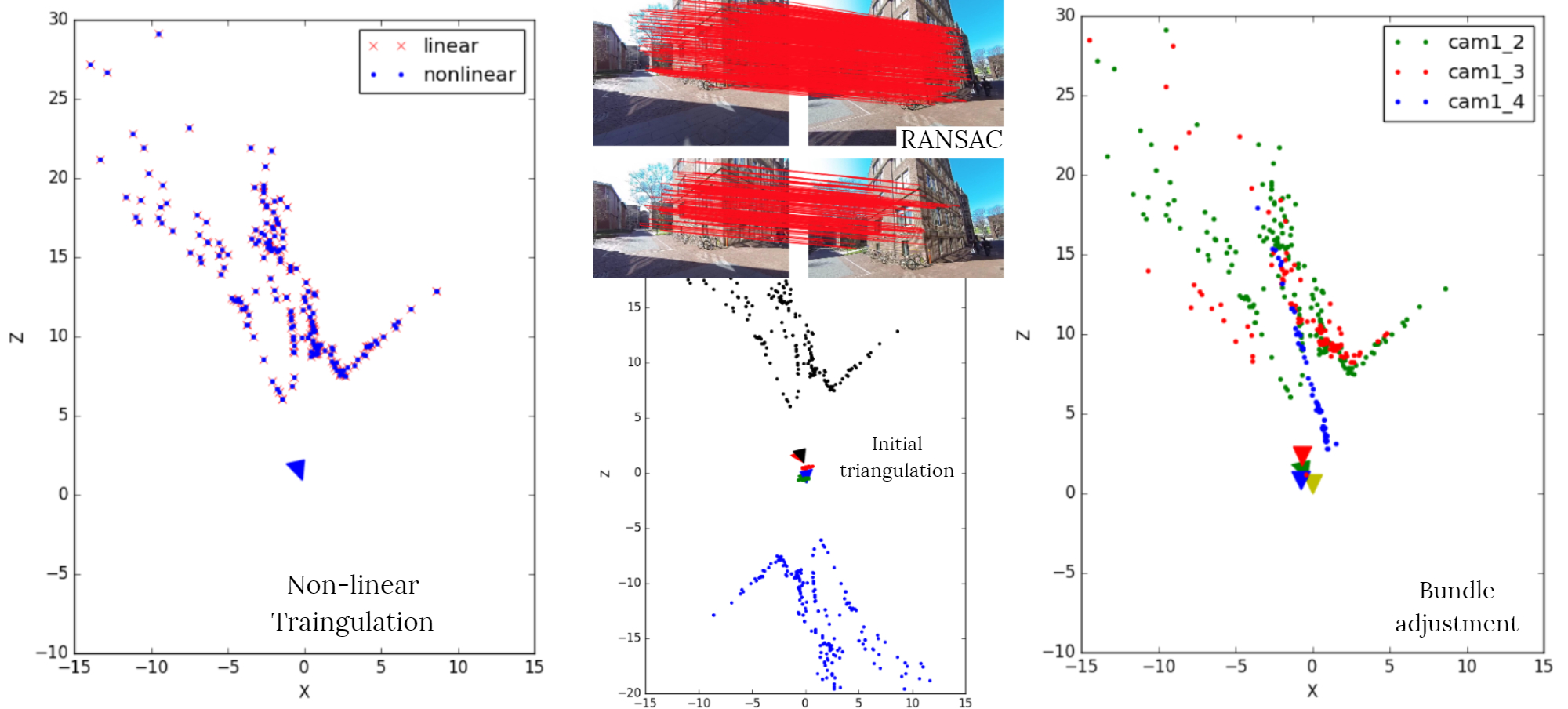
SFM is about reconstructing a whole 3D scene and simultaneously obtaining camera poses from a set of images taken by a monocular camera at different locations and positions of a scene. The problem here is often referred to as Structure from Motion (SFM).
An unsupervised learning approach for predicting the monocular depth and ego-motion from the video sequences. I improved the end-to-end learning approach presented in SfMLearner. In contrast to the original SfMLearner, our training data was limited to a subset of the original KITTI dataset. I used ResNet architecture for depth estimation, with SSIM and forward-backward consistency loss, which is from GeoNet. The evaluations and comparison showed the effectiveness of my approach, which improved the abs_rel depth metric of SfMLearner by 18%.

An end-to-end pipeline of swapping two faces in a video, by using both classical (Dlib library) and deep-learning (PRNet) methods for getting facial fiducials. The Face Swap in two scenarios is shown, first between two faces in the same video and in second, a face in a video with a face in from given image. The resulting videos can be viewed here.

In this project, two or more images were stitched together into one seamless panorama image. The estimation of homography between the pictures performed in both classical (Harris corners, RANSAC) and deep-learning methods (HomographyNet). The deep-learning approach had both supervised (HomographyNet) and unsupervised methods. Although, the deep-learning techniques were able to provide satisfactory results on the synthetic data but not between two images to be stitched. Hence, I performed the stitching of images using the classical approach.

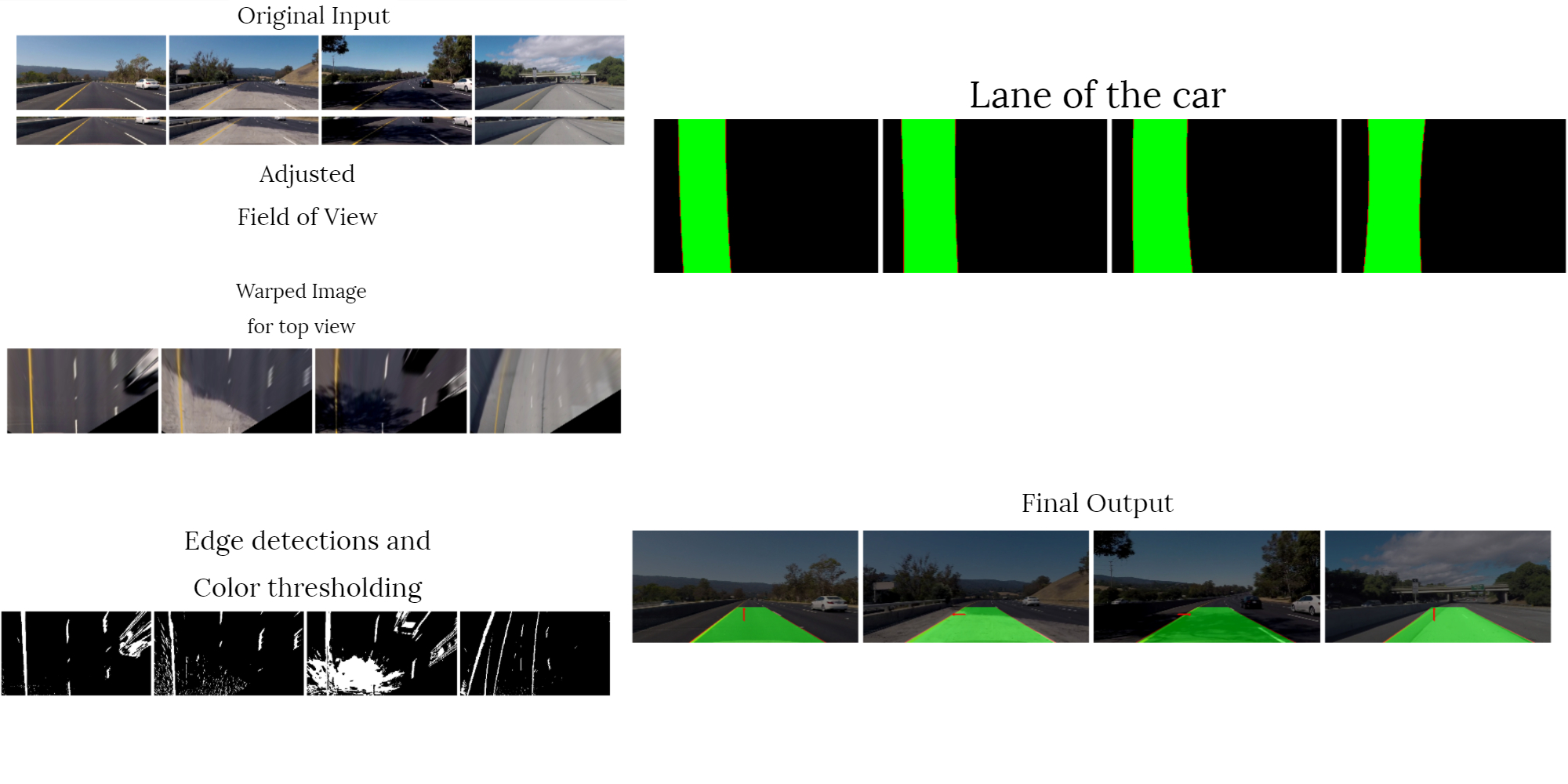
Lane Detection on a video sequence taken from a moving car. An algorithm was designed to detect lanes on the road and to estimate the road curvature to predict the turns made. The results are in these videos.
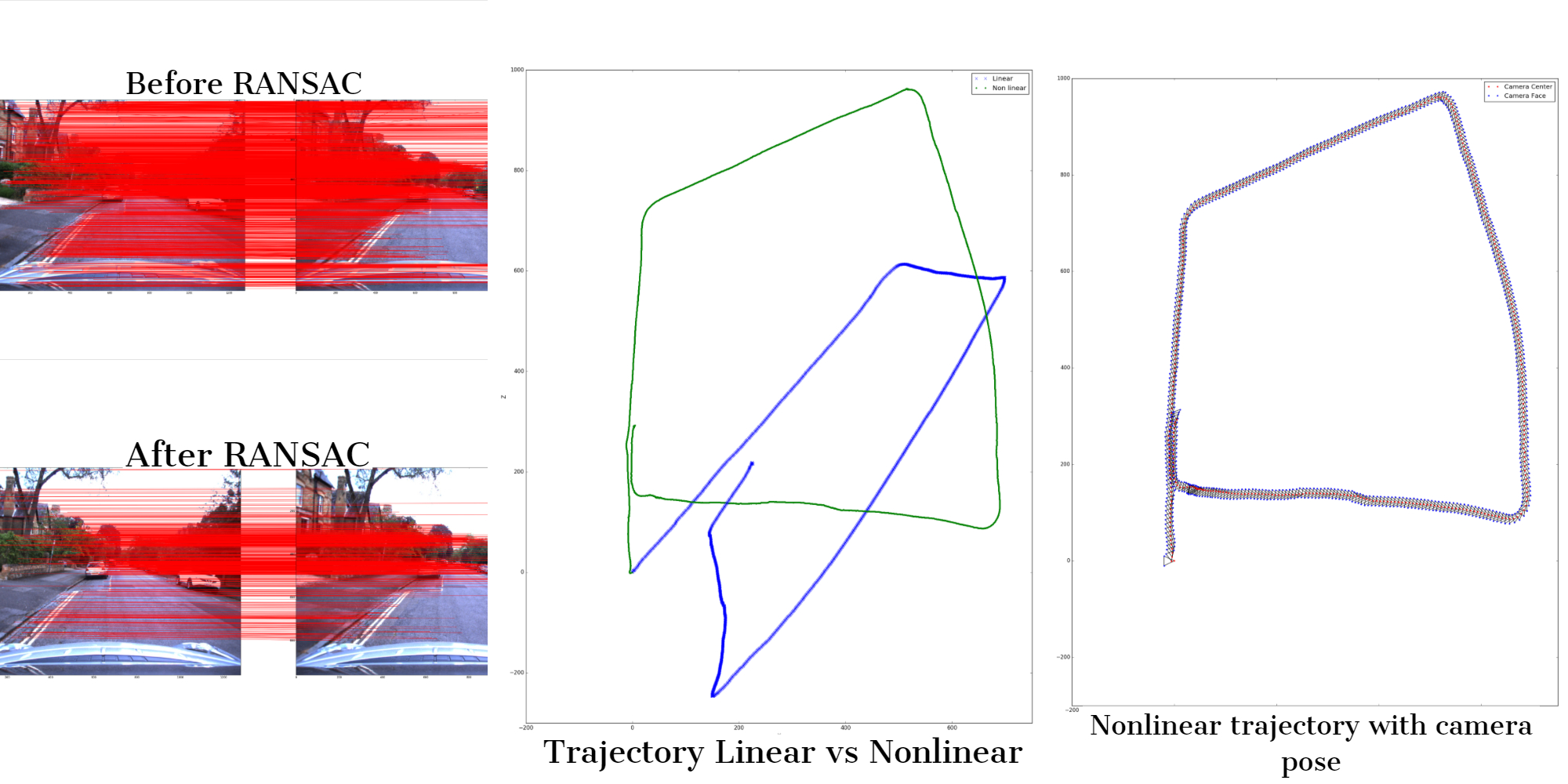
In Visual Odometry, by utilizing successive frames of a car's movement, I generated a plot of the camera's trajectory, i.e., the path taken by the vehicle. Non-linear optimizations were performed to achieve the right pose of the camera. The input videos are from the Oxford dataset.
Detection and recognition of the traffic signs are carried out in this project. In the detection stage, a pipeline was made to extract the possible candidates that contained the traffic sign. And the other part was to correctly classify the detected signals using SVM (Support Vector Machine). A video of a moving car converted into the output, in which the signs are identified and labeled accordingly. The SVM was able to classify 62 signs provided correctly with an accuracy of 99.76% on the test data.

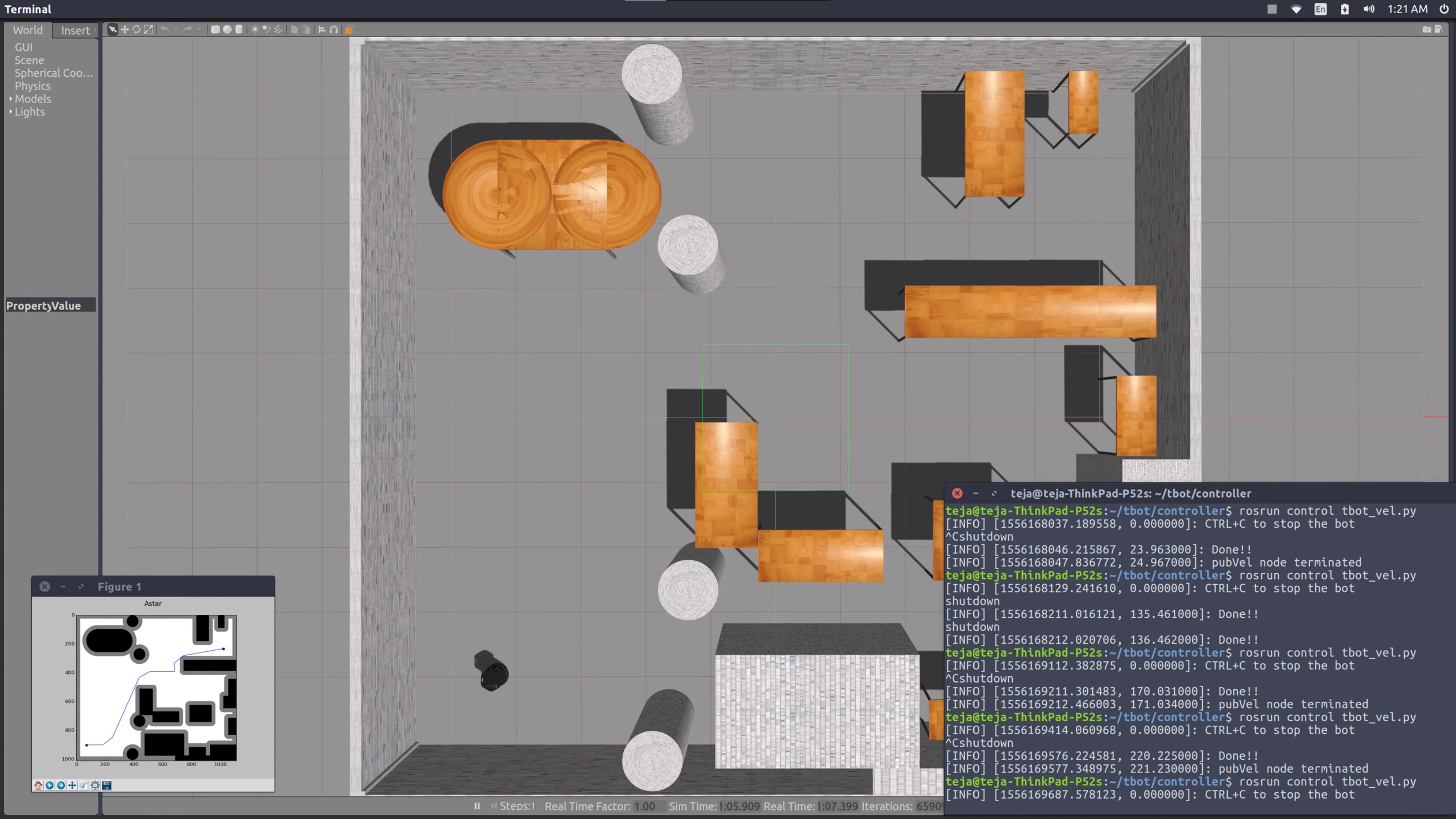
Via Path Planning, I Implemented the most popular path planning algorithms used in robotics such as A-Star, Dijkstra, and Simple Breadth-First Search. Also, the picture below is from the implementation of the A-Star algorithm for the differential drive to find the path that the turtle bot had to traverse to reach the goal position while avoiding the obstacles.
© Gnyana Teja Samudrala 2019